Deconstructing a git commit
Every git repo contains a .git directory and everything git tracks or is aware of is stored in this directory, and that is where all the magic happens. In this blog We’ll break down each internal step Git takes — from hashing content to building trees and commits — demystifying what really happens when you run git commit command.
Let’s take the first step and create a new Git repository with the git init command. Now, the moment we run this command, git creates the .git directory and other files to track our project. Lets peek inside this directory to understand its basic structure and files.
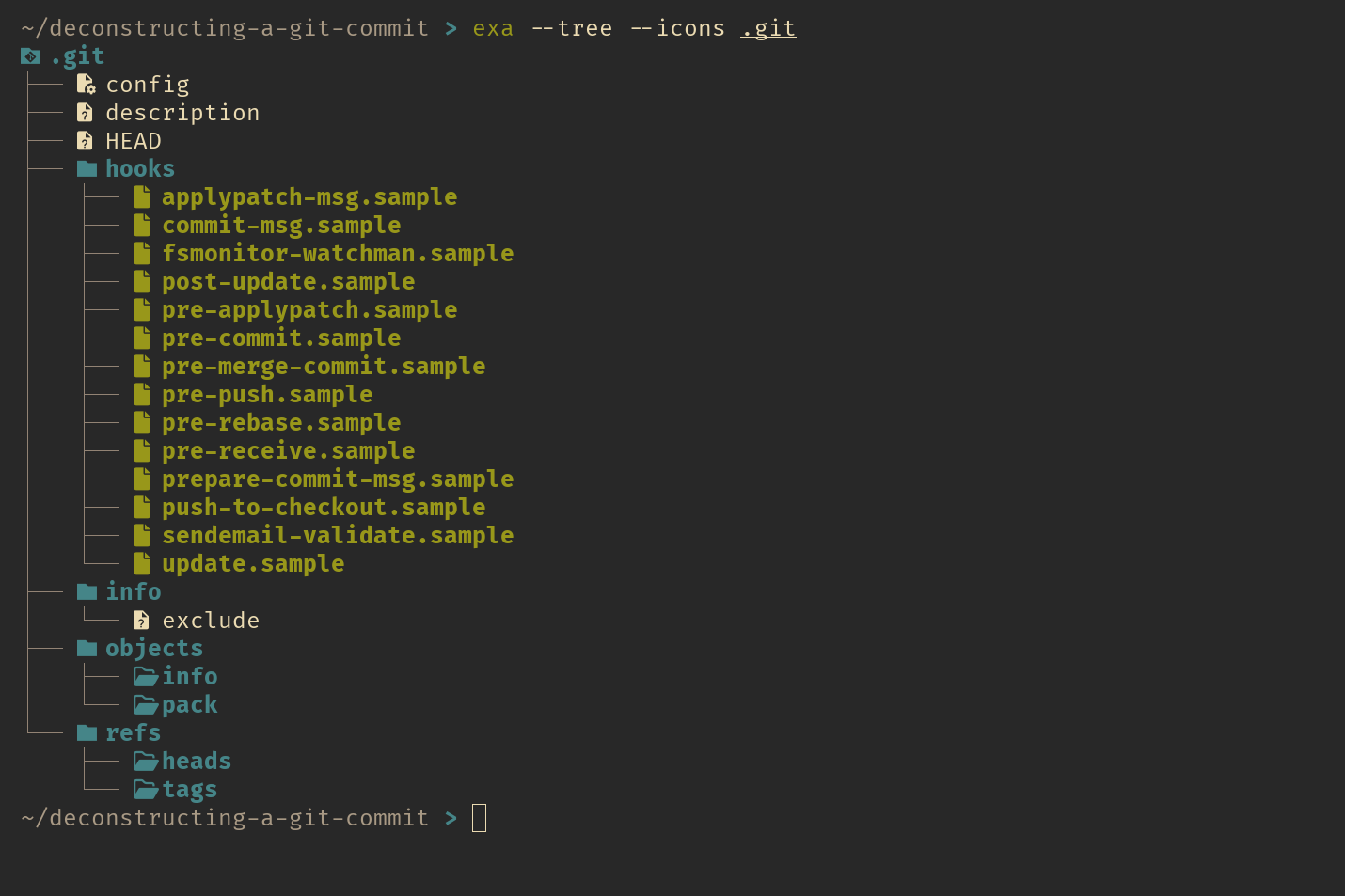 directory tree of a fresh git repo
directory tree of a fresh git repo
I’ve given a quick overview of what each file and folder inside the .git directory does. Don’t worry if it’s still a bit fuzzy right now—that’s completely normal! Once we go through the process of making our first commit, everything will start to make sense.
So, let’s jump right in by making our very first commit and see how things change in the .git directory.
First, let’s create a file named hello.txt and with the text “hello, world!” inside it. Then, we’ll commit it and see what happens!
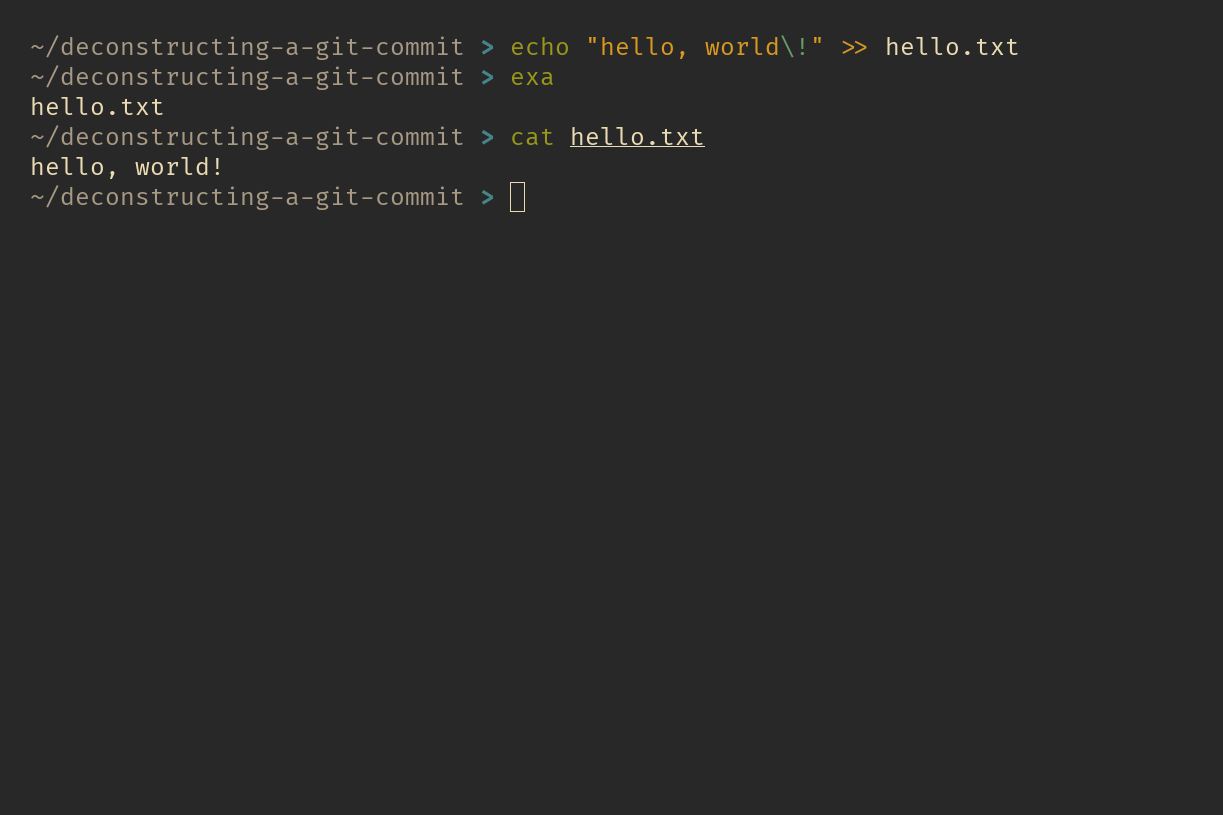 hello.txt
hello.txt
Now let’s create our first commit by commiting hello.txt file to git and see how it changes the .git directory.
~/deconstructing-a-git-commit > git add hello.txt
~/deconstructing-a-git-commit > git commit -m "Initial commit"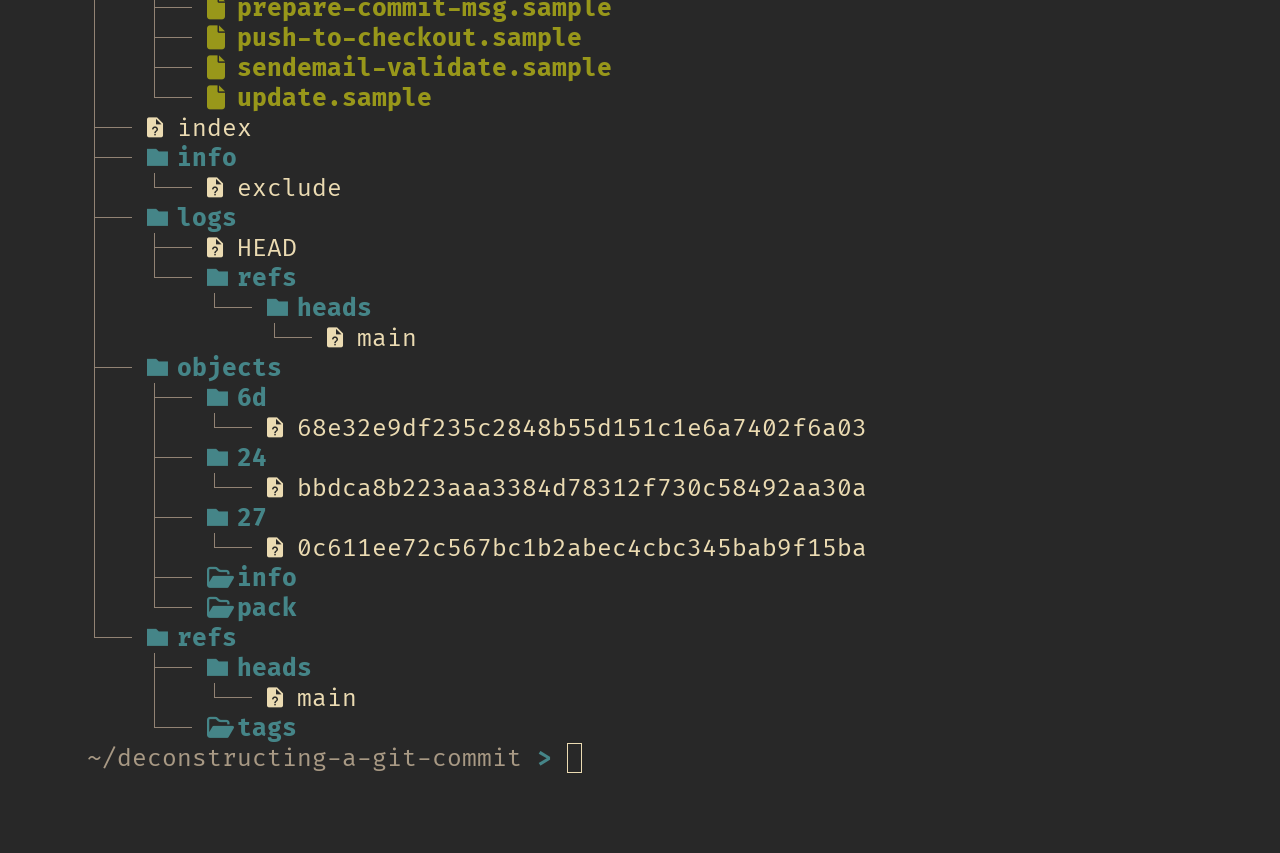 you might have files with different names, since these file names depend on your git configurations
you might have files with different names, since these file names depend on your git configurations
After the commit, you might notice that three new directories have popped up in the objects directory, each containing a single file. So, what are these files all about, and why did Git create them?
In Git terms, these files are called object files. Git uses four different types of object files:
- Blob: This is where Git stores the actual contents of a file.
- Tree: This holds information about files and directories, such as their names and permissions. It also references other tree objects.
- Commit: A commit refers to a specific tree object (think of it as a snapshot of the project at a particular moment in time). It also stores metadata like the timestamp, author, and a reference to previous commits (the parent commit).
- Tag: A tag marks a specific commit as important. For example, tags are often used to highlight release versions.
If you print the content inside any of these object files using the cat command, you’ll just see a bunch of gibberish. That’s because Git compresses the contents of these files with Zlib before storing them.
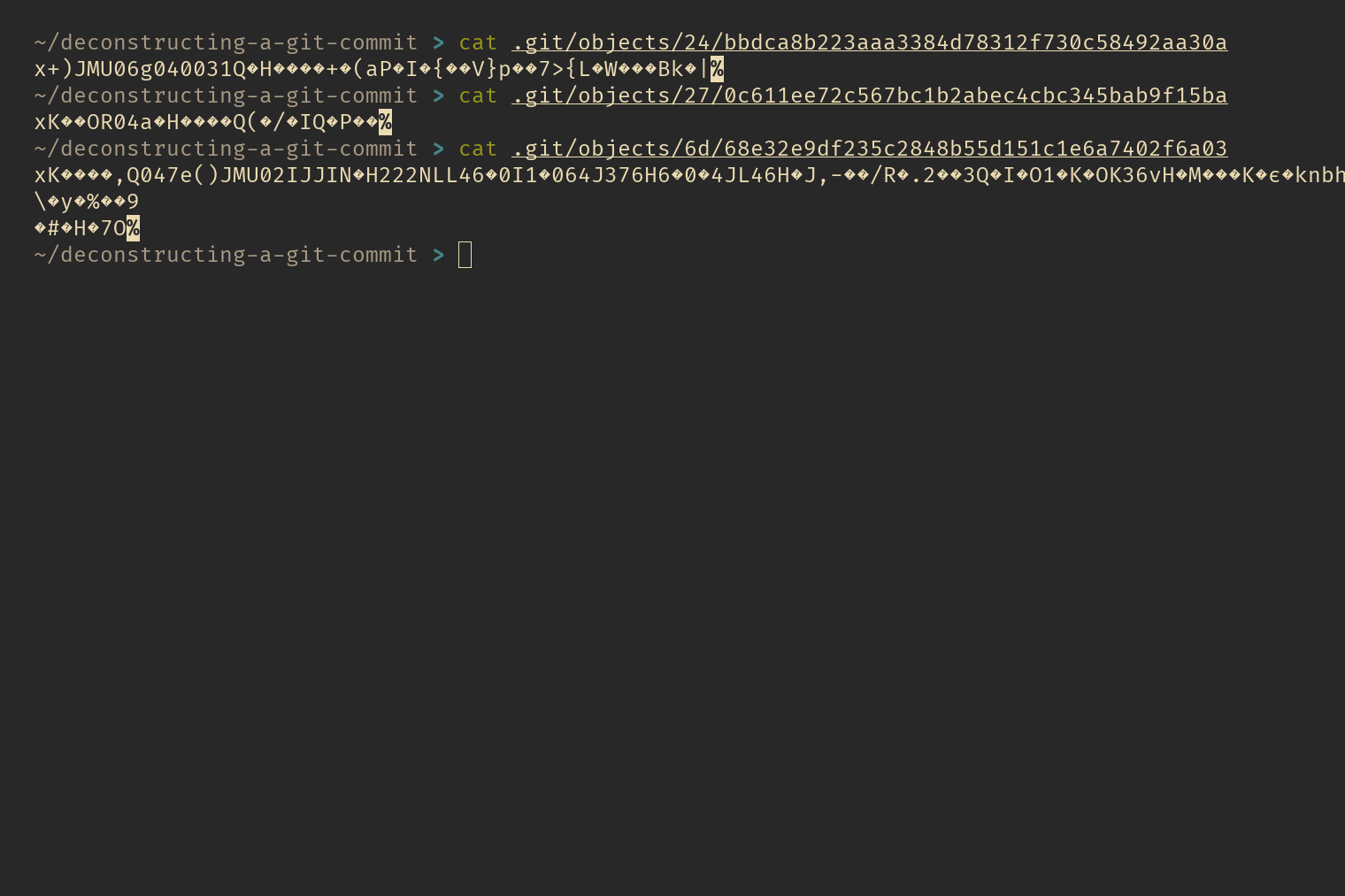 raw object files
raw object files
You can decompress these files using any tool that supports Zlib. For example with the zlib-flate command on linux by installing qpdf package or zlib formula via homebrew if you are on mac. Once installed you can use zlib zlib-flate -uncompress <filename>. Or you can use any other tool that allows you to decompress with Zlib—whatever works best for you!
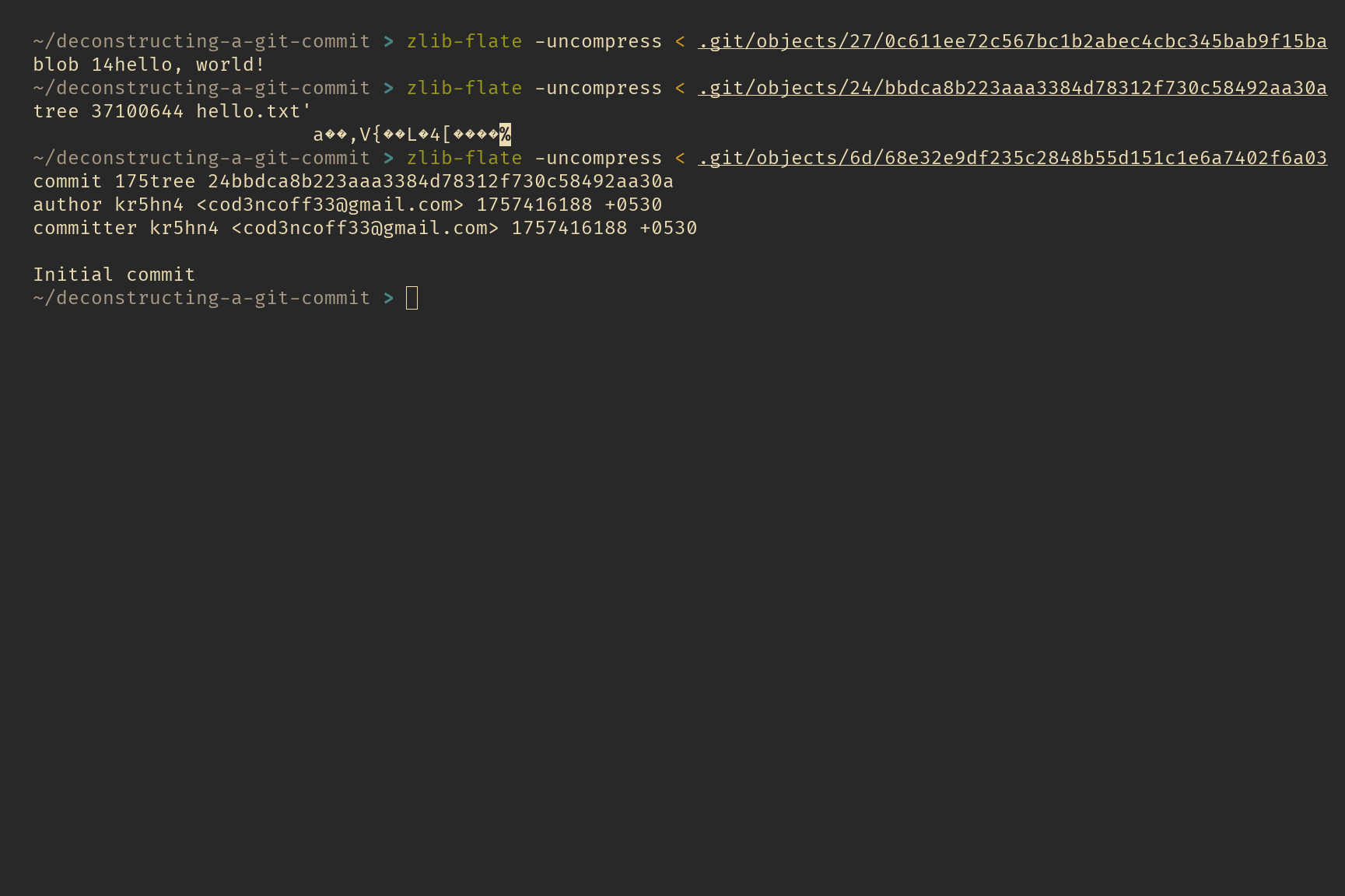 decompressed object files
decompressed object files
If you calculate the SHA-1 hash of any of these object files after decompressing them, you’ll notice something interesting—the SHA-1 hash matches the file’s name, including the two-character prefix of the folder where the file is stored. This is how Git names and organizes its object files.
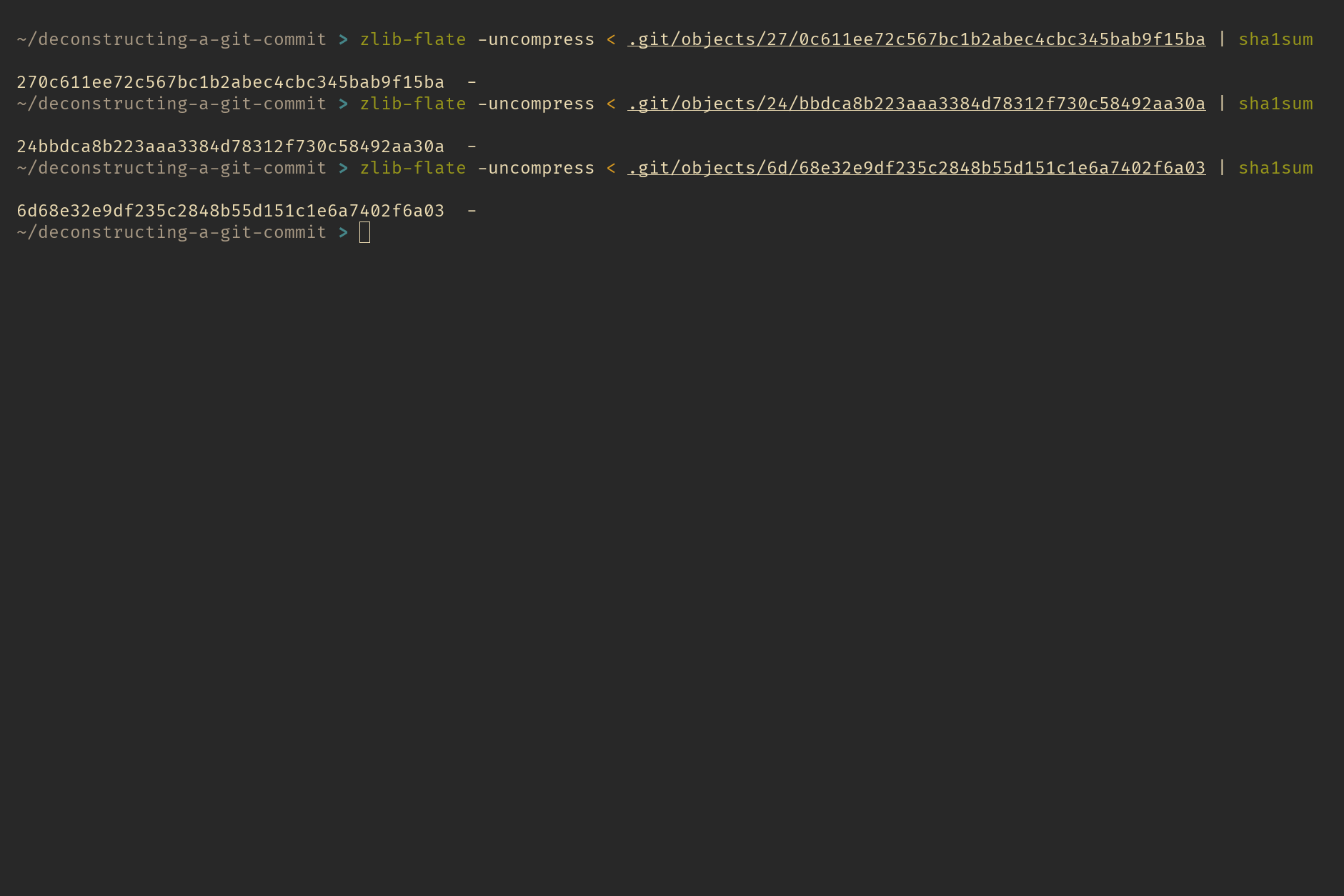 shasum of decompressed object files
shasum of decompressed object files
This happens because Git names its object files based on their content. This method of naming files by their content is what we call content-based addressing i.e. name of the file is derived based on its content, and it’s one of the reasons Git is also known as a content-addressable filesystem.
Now, let’s break down what just happened when we made that commit and see if we can replicate the hashes ourselves. Creating a Git commit happens in two stages: staging and committing. But for simplicity, we’ll treat these two steps as one. (If you’re curious about why Git uses a staging area, you can read more about it here.)
When we create a commit, one of the first things Git does is create a blob object for each file in the repository. In our case, we only had one file—hello.txt. So, Git took the content of hello.txt (just the content, without any additional information like the file name or permissions), prefixed it with the word “blob,” followed by the file size and a NUL character. Then, Git calculated its SHA-1 hash and used that hash as the file name. Finally, Git compressed the content with Zlib before storing it in the objects directory.
 blob object breakdown
blob object breakdown
Let’s verify that this is true by running the following command.
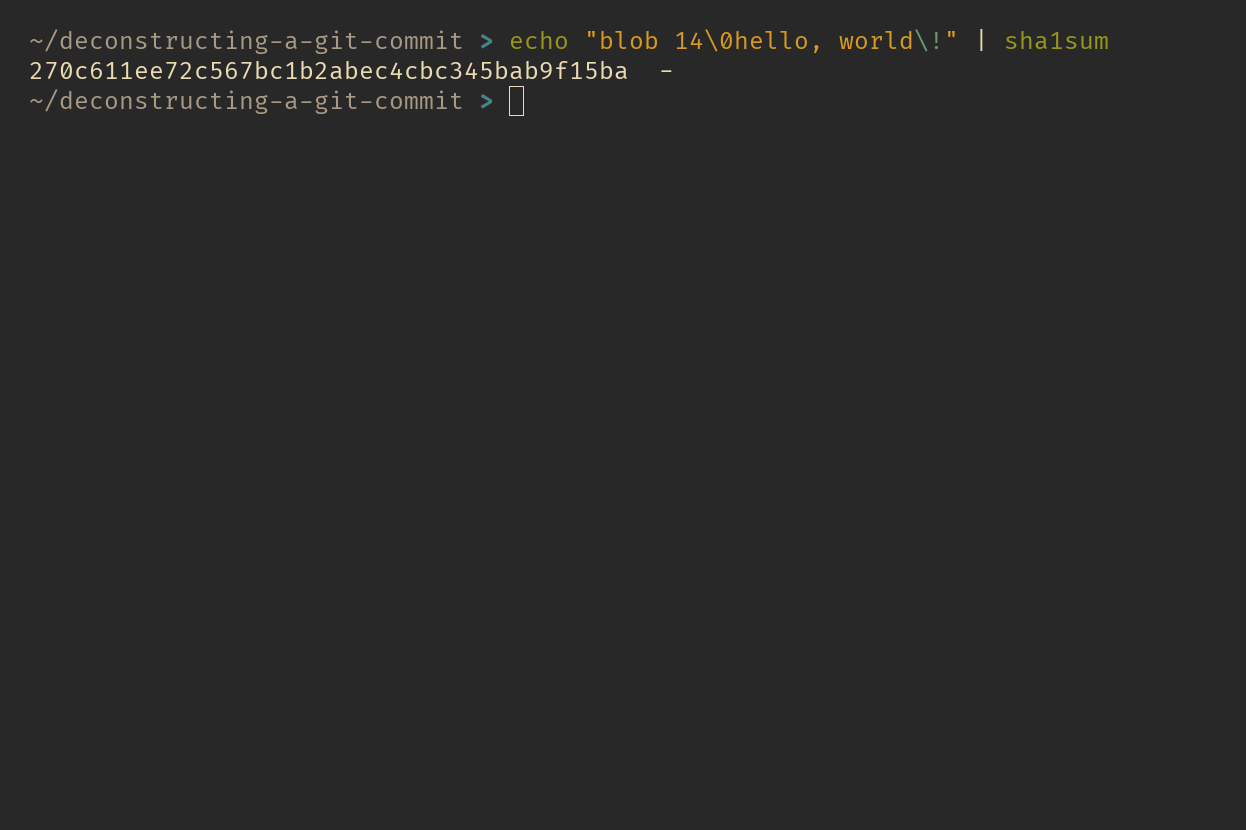
As you can see, the hash value matches one of the object names in the objects directory from our first commit. Git takes the first two characters of the hash as the directory name and uses the rest as the file name. This is a clever trick Git uses to prevent file system errors since many file systems have limits on the number of files you can store in a single directory.
So, that’s how Git stores the content of files, but how does Git know which file this content belongs to?
That’s where another type of object, called a tree object, comes in. A tree object is a simple structure that holds references (or pointers) to blob objects and other tree objects. Essentially, it represents the contents of a directory and includes additional details like file mode, the file or directory name, a reference to the SHA-1 of the blob or tree object, and some metadata.
In our case, we had just one directory—the working directory—with a single file in it, hello.txt. If we had more files or subfolders, they would all be represented in this tree object. And here’s the tree object structure broken down:
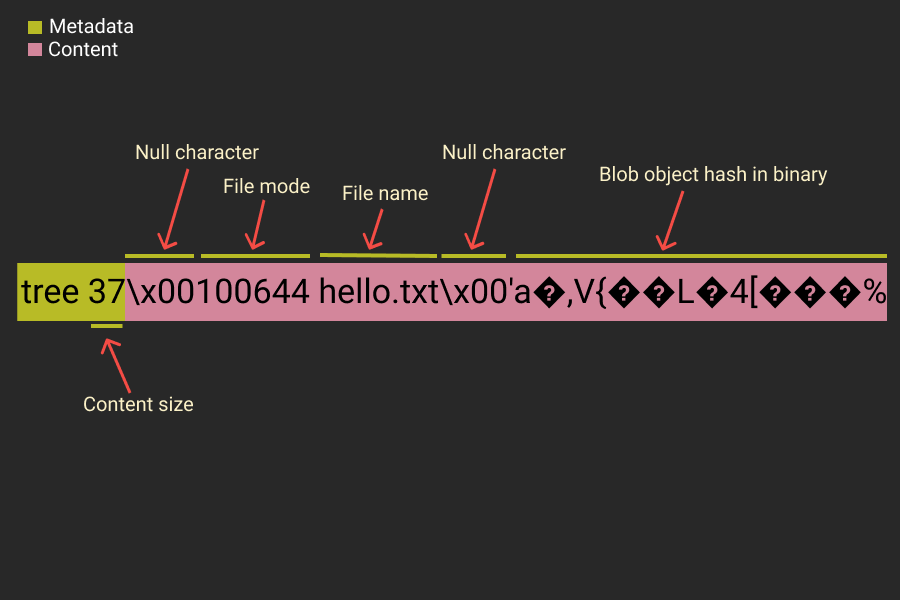 tree object breakdown
tree object breakdown
The first six characters after the NUL character (100644) represent the file mode, Git uses the following modes:
- 100644 for a normal file
- 100755 for an executable file
- 040000 for a directory
- 120000 for a symbolic link and after that comes the type of object whether tree, blob or commit followed by the SHA-1 hash of it and finally the file/directory name. An object referenced by a tree may be a blob, representing the contents of a file, or another tree, representing the contents of a subdirectory.
You can use the following command to recreate the tree hash:
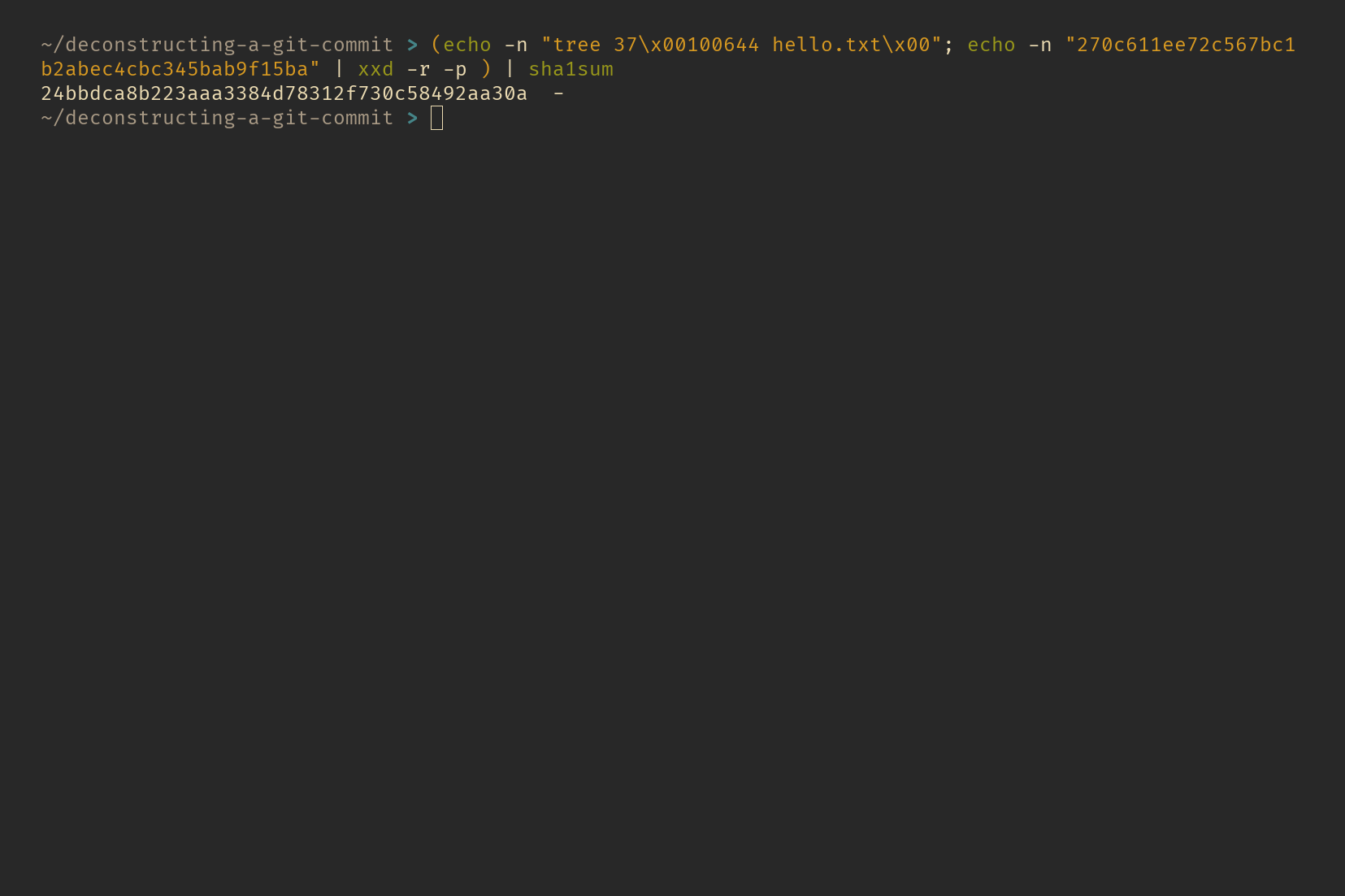 Recreate tree hash
Recreate tree hash
The tree object is a bit unusual. It doesn’t include a newline character at the end, which is why we need to pass the -n flag to echo—this tells echo not to add the newline, as it normally would. Additionally, the tree object stores the hash values in binary form. Why does Git do this? Well, nobody really knows for sure. It’s just one of those quirks of Git’s design.
Finally, Git creates a commit object to tie everything together. In our case, the commit object is 6d68e32e9df235c2848b55d151c1e6a7402f6a03. This is the hash you see when you run the git log command. The commit object holds crucial information about the commit: who made the commit (the author), who applied it (the committer), the commit message, a reference to the tree object representing the state of the working directory, and a reference to the parent commit (if there is one). Since this is our first commit, there’s no parent—making it a root commit.
Now, let me show you how Git calculated the SHA-1 sum of this commit object..
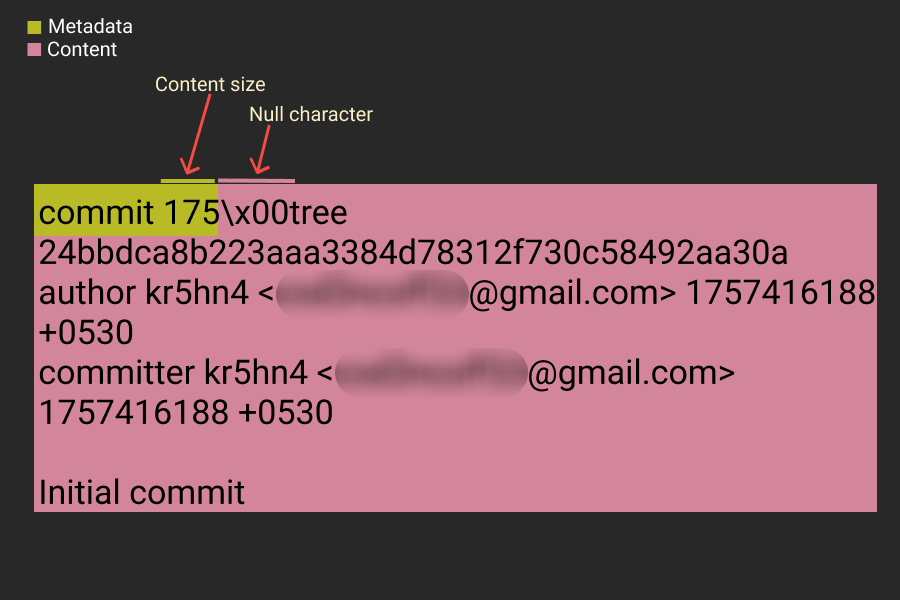 commit object breakdown
commit object breakdown
You can use the following command to recreate the commit hash: 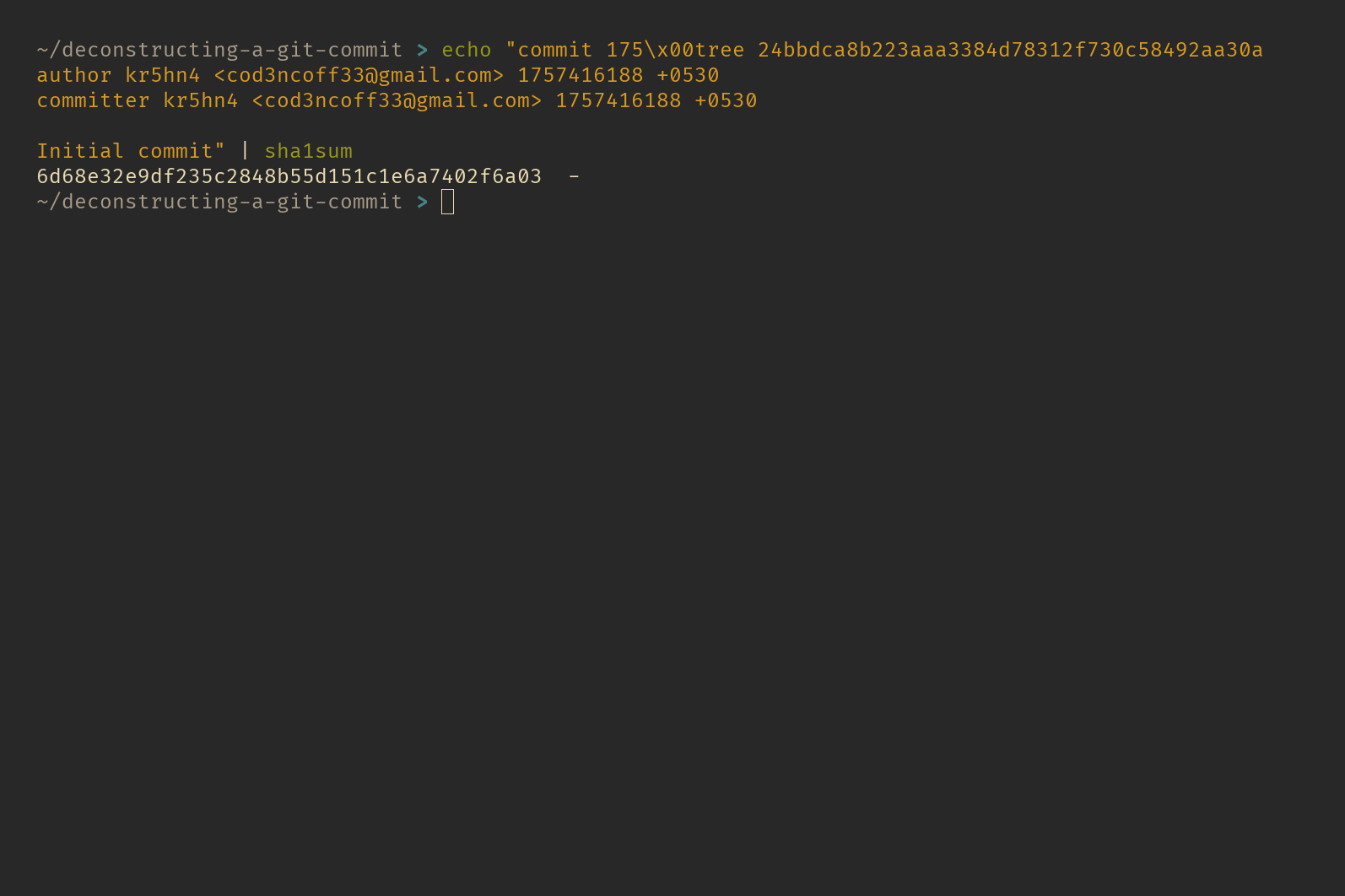 recreate commit hash
recreate commit hash
And this is how Git links commits to trees, and trees to blobs.
A common misconception is that Git stores only the changes between commits, but that’s not exactly how it works. Instead, each Git commit is like taking a snapshot of the entire working directory at a particular point in time. This snapshot consists of commit, tree, and blob objects. So, every time you make a commit, Git saves the entire contents of the working directory in the .git directory.
You might be thinking, “Isn’t that inefficient in terms of disk space?” Actually, no. Thanks to Git’s content-based addressing, it reuses the same blobs and tree objects across multiple commits if the contents of the files or directories haven’t changed. So, Git efficiently manages storage by avoiding duplication.
Here’s a visual representation of a sample repository, showing how Git connects commits, trees, and blobs together.
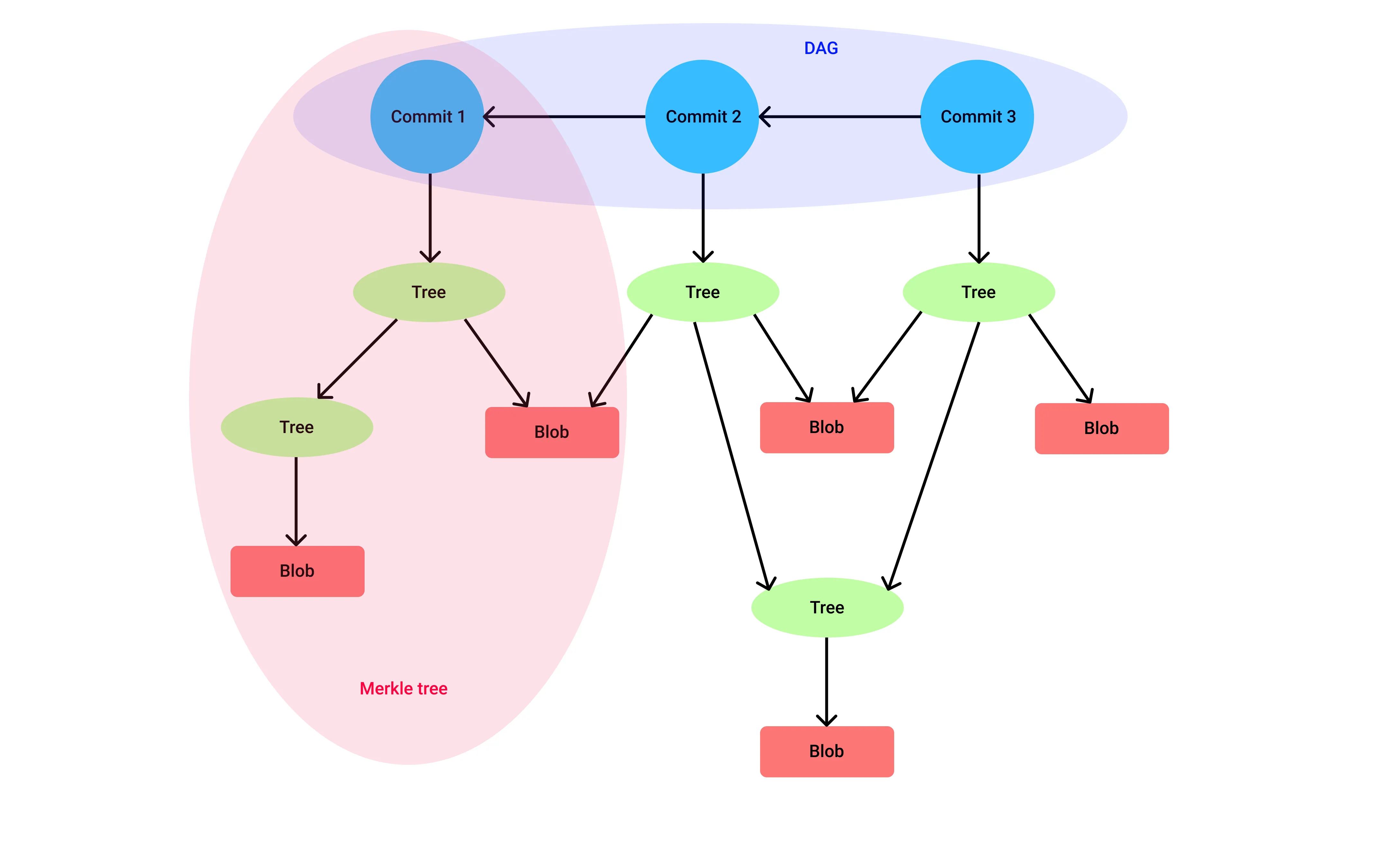 This type of data structure is also called a merkledag, because its a combination of merkle tree and a DAG.
This type of data structure is also called a merkledag, because its a combination of merkle tree and a DAG.
That’s all for this post. In the next one, we’ll dive into how Git handles branches, defines tags, and explores various Git configuration options. Stay tuned!