Making sense of treesitter
 Source code to CST conversion
Source code to CST conversion
What is the Concrete Syntax Tree (CST)?
CST is a hierarchical representation of your source code which includes every detail, including punctuation and comments. Because of its hierarchical structure it can be navigated and queried very easily as opposed to the linear source code format.
The treesitter parser for a given language converts your code from linear text format to a hierarchical structure which is more easy to analyse and query. In this blog, we will take the example of Javascript, we will generate the parser for javascript and later use the tree-sitter CLI to query and highlight javascript files with treesitters’ Javascript parser. We will even look at how to use/setup the features of treesitter within neovim. So lets go over this tree format and understand what exactly does it comprise of.
The CST comprises of nodes, each node in the CST correspond to a syntactic element or construct in the source code, such as an expression, statement, or punctuation.
Treesitter produces two types of nodes:
- Anonymouse nodes
- Named nodes
Tree-sitter distinguishes between anonymous and named nodes to make it easier to analyze code. Anonymous nodes represent things like commas or parentheses, which are important for code structure but not for understanding what the code does. Named nodes represent meaningful elements like functions or variables. By focusing on named nodes, you can ignore unnecessary details, making code analysis simpler and more like working with an abstract syntax tree (AST).
 various parts of CST
various parts of CST
Every named node has the following details in the CST:
- A Node type
- Position - the position stores the start and end position of the row/column number. (row/column number start at zero)
- Optional - Child or Sibling nodes (child nodes may have fields)
- field is a named reference that specifies the relationship of a child node within its parent node.
Nodes in a CST are related through parent/child or sibling relations. In order to understand this relations, we must have a good grasp of the languages grammar, for example if you check the Javascript’s grammar in tree-sitter-javascript repo, you will see the grammar file has a rules property, tree sitter uses these rules and other details in the grammar files along with the help of some other files in the repository to generate the parser.
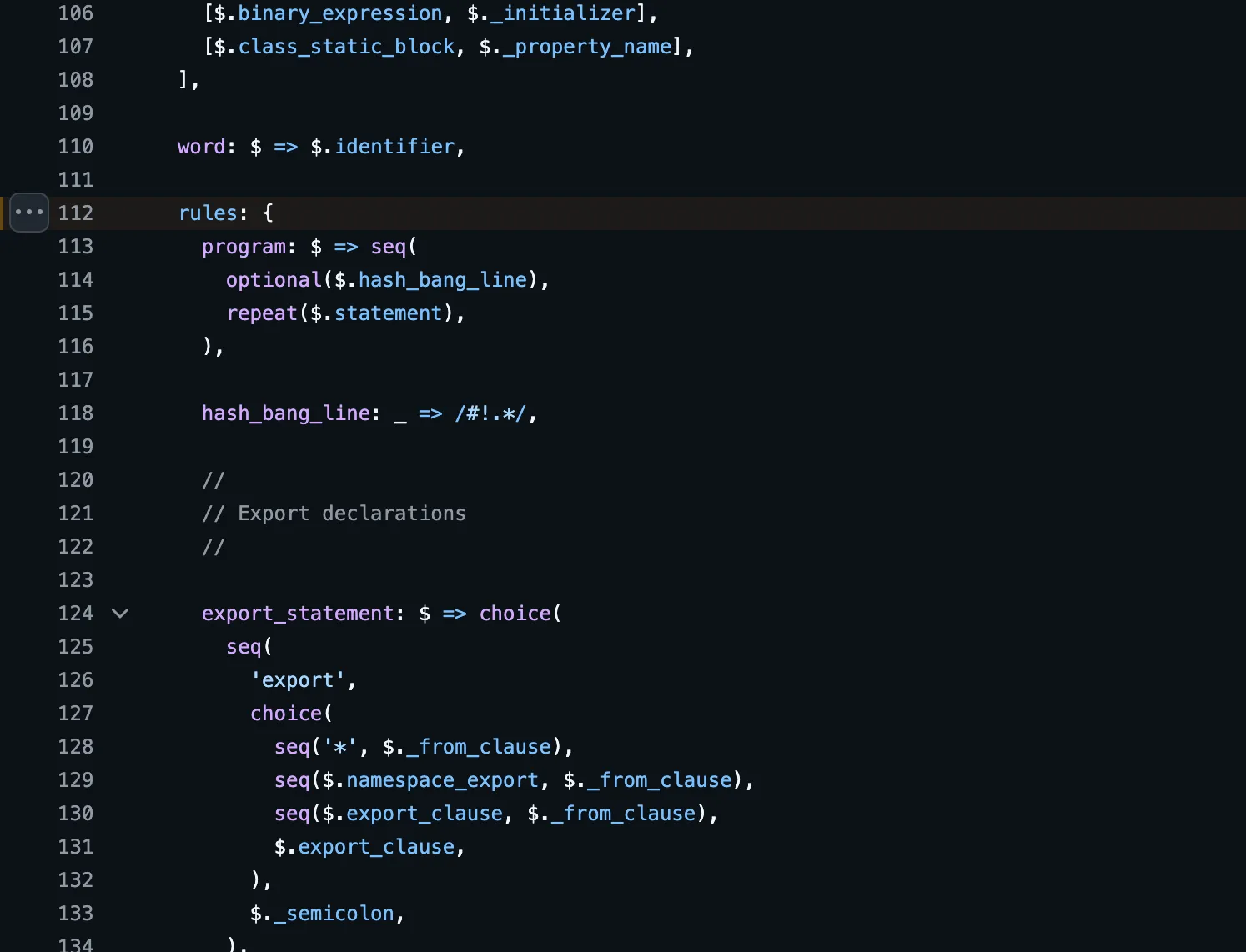
Using the tree-sitter cli
Lets use the tree-sitter cli to parse and highlight a sample Javascript file.
- First install the cli :
npm install -g tree-sitter-cli- Clone the tree-sitter-javascript repo to build the parser for Javascript :
git clone https://github.com/tree-sitter/tree-sitter-javascript- cd into the cloned folder:
cd tree-sitter-javascript- Generate the javascript parser (the tree-sitter-javascript repo has all the details like the grammar.js and other files to generate the parser):
tree-sitter generate- Inialize the tree-sitter config:
tree-sitter init-config- Update the config with the following values:
{
"parser-directories": [
"[parent directory name where you cloned the tree-sitter-javascript repo in step 2]",
],
"file-types": {
"js": "javascript"
},
rest of the config...
}Now that we have the javascript parser setup with treesitter, we can finally use it to parse and highlight javascript code.
Create a javascript file with the following contents
function add(a, b) {
return a + b;
}- run
tree-sitter parse app.jsto produce the CST.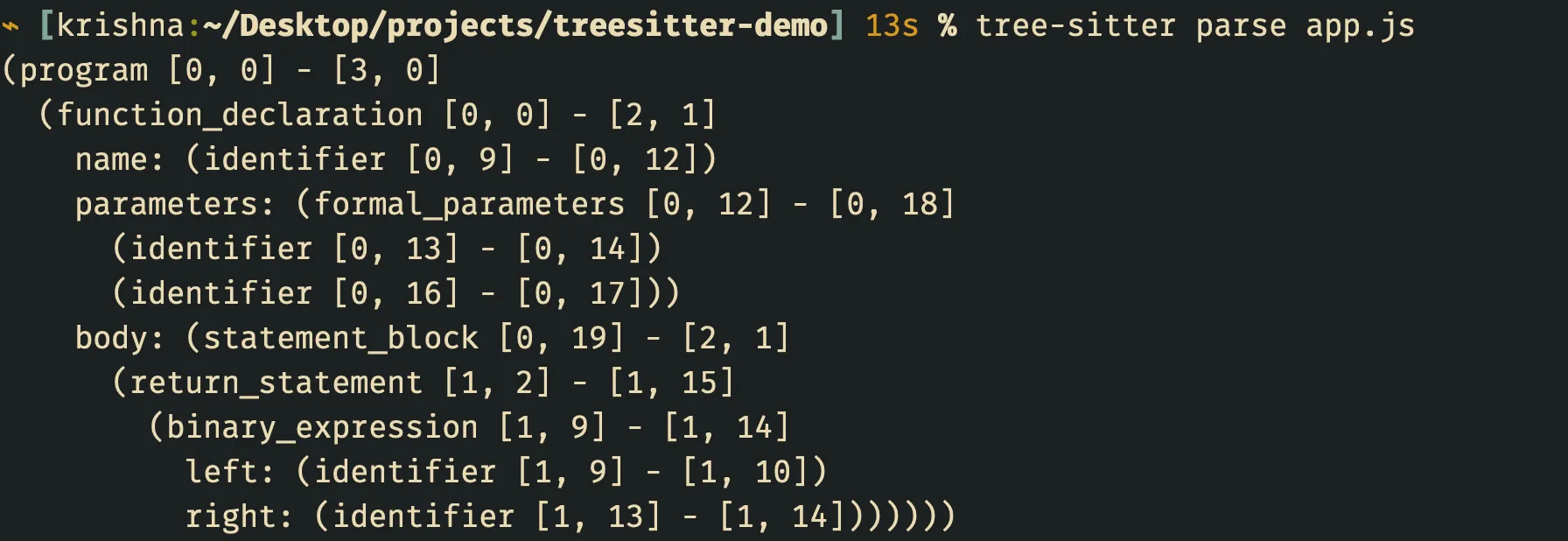
- run
tree-sitter highlight app.jsto highlight the file.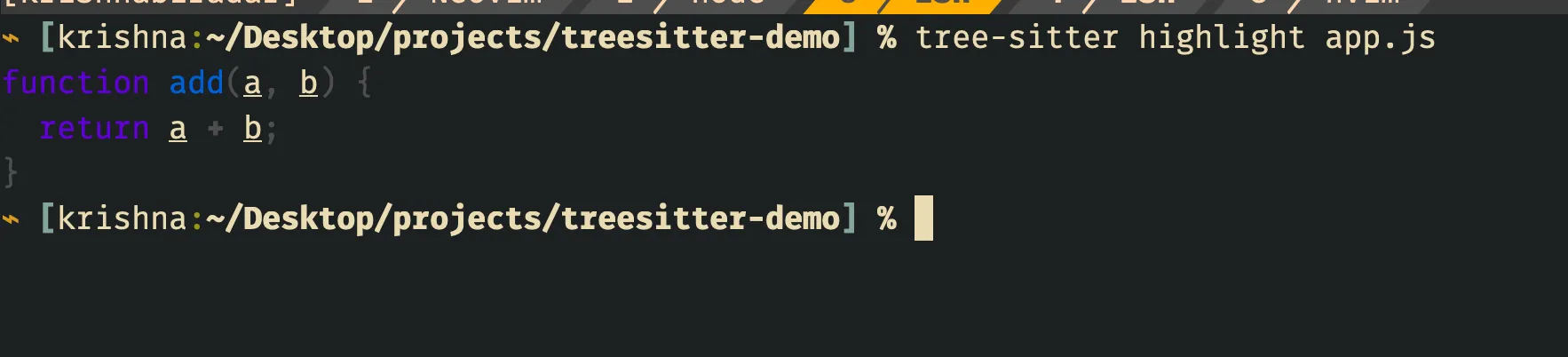 If you are interested in exploring tree-sitter’s cli further then you can run
If you are interested in exploring tree-sitter’s cli further then you can run tree-sitter -hfor further help.
Treesitter query language
To analyse our code treesitter provides a very simple but powerful query language. Queries are just patterns to match the nodes in the CST. Each pattern must be an S-expression, which can match zero or more nodes in the CST.
To match a function declaration for example we can use the query:
(function_declaration)however, using just that is not enough we need capture it too, you can use the following syntax to capture it.
(function_declaration) @function.declarationWhy capture, you ask? Well, sometimes we might be writing queries to find specific code patterns. For example, if we want to find all the functions that contain if statements, but are only interested in capturing the function names, we could write a query like this:
(function_definition
name: (identifier) @function.name
(if_statement)
)In the above case, we are using the @function_name capture to extract just the function names, which is the information we care about. This is why capturing is useful—it allows us to focus on the specific data we need, even when querying for larger patterns.
Captures allow you to associate names with specific nodes in a pattern, so that you can later refer to those nodes by those names. Capture names are written after the nodes that they are capturing, and start with an @ character.
To match child nodes, for example to capture a function name:
(function_declaration
name: (identifier) @function.name
) If you want to learn more about the query language and its syntax, treesitters’ documentations has covered it in full details here
Using treesitter playground in neovim
Neovim has treesitter support built-in, but you still need to install parsers for your languages. You can install parsers with the nvim-treesitter plugin. Once you have the plugin you can run the following commands
- :InspectTree - to open the CST window
- :EditQuery - to open a window for writing queries
Below is a short video which shows how to do it
Tree-sitter is a game-changer for syntax parsing and code analysis. Its flexibility and efficiency make it a must-explore tool for developers. If you’d like to talk more, feel free to message me—I’m always happy to chat about dev tools, and programming languages. Thanks for reading, and happy coding!